Evidence Library#
1. What is this page#
The Evidence Library is your brand's source vault — the page where you save trusted references (research papers, government documents, certification standards, expert articles, industry reports) that will later support the claims in your content.
It is not a writing surface. It is a manual-first library you build once and reuse forever. Each row is a single, specific source. After you add it, the citation engine pulls from this library when drafts are generated, so you never re-enter the same source twice.
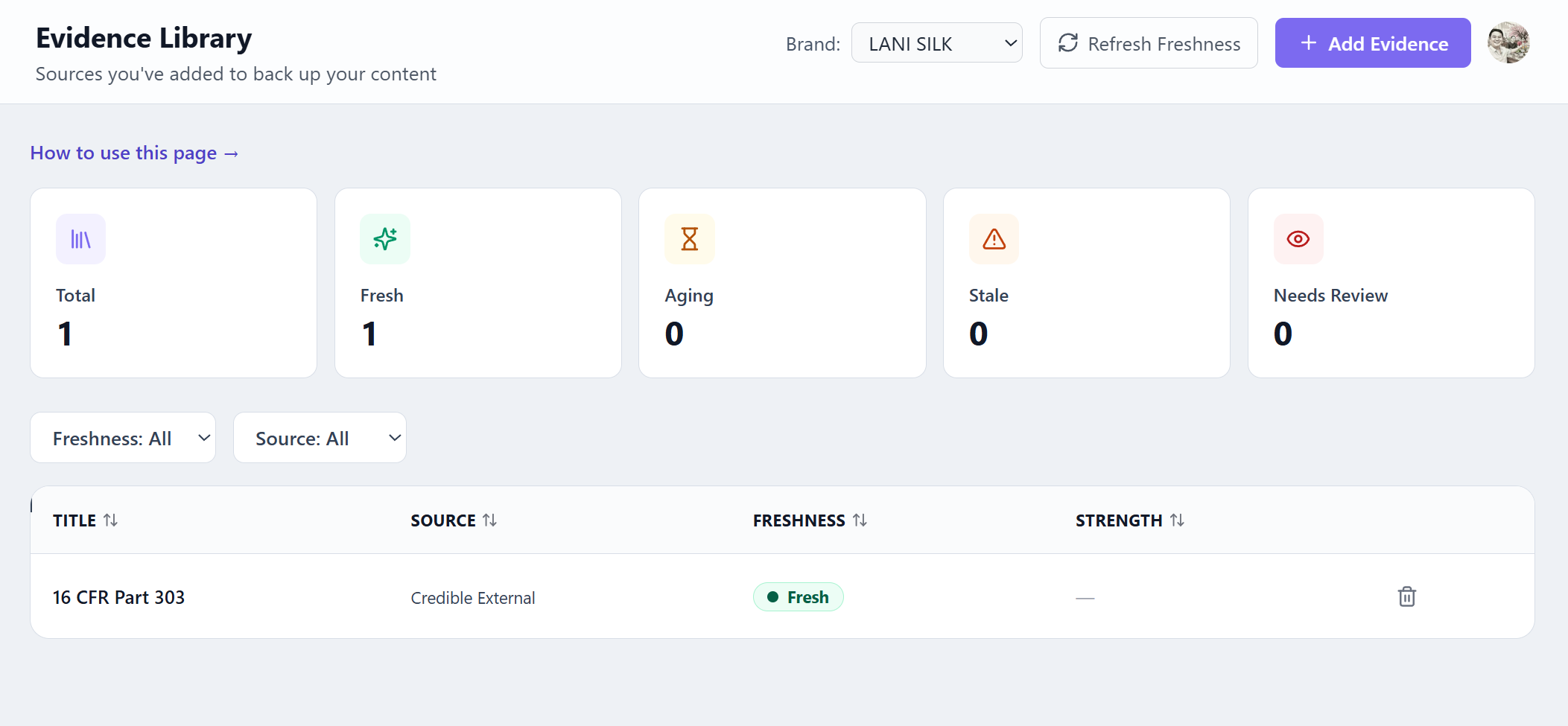 123456
123456- 1Brand selector — each brand has its own library
- 2+ Add Evidence — opens the modal to add a new source
- 3Status cards — aggregate count by freshness state
- 4Filter row — narrow the list by freshness or source type
- 5Freshness column — engine-managed status pill
- 6Strength column — reviewer-set 0–100 score (empty until rated)
2. Why it matters#
- Trust signal — content backed by named sources reads as more credible to humans and to AI search engines. This matters most for YMYL-adjacent topics where readers expect verification.
- AI search citation readiness — Google AI Overview, Perplexity, and ChatGPT Search tend to cite content that pairs a specific data point with a named source. A rich library raises the chance your content gets cited.
- Reuse across drafts — one well-curated source can support a dozen articles. You stop re-Googling the same fact every time you write.
- Anti-overclaim guard — when the GEO Validator runs, the library lets you turn vague language into supported facts. "Silk improves sleep" becomes "22-momme mulberry silk reduces nocturnal awakening in [study population] per [named study]." The validator's GV-10 overclaim rule rewards precision.
- Freshness tracking — every row carries a freshness status. When a source goes stale, the Refresh Engine surfaces it so your content stays current.
3. Where it fits in the workflow#
Brand → Discover → Brief → Outline → Draft ← (Evidence Library plugs in here) → Review → Validate → Publish
You curate evidence before or during drafting. The Draft Engine reads from your library at generation time. The GEO Validator checks evidence coverage as part of publish readiness — standard mode requires ≥50% coverage of claims; sensitive YMYL mode requires ≥70%.
Empty library means drafts come back with [NEEDS_EVIDENCE] flags everywhere and will not pass the validator. Rich library means smooth, evidence-backed drafts on the first pass.
4. How to use it#
- Navigate to /create/evidence in the app.
- Select your brand from the top-right dropdown.
- Click + Add Evidence.
- Fill the form — five fields, in order:
- Title (required) — display name for the source
- Source type (required) — pick the most specific tier (see below)
- Source URL (optional) — leave empty for internal data or expert quotes
- Source date (required) — the source's publish date, not today's date. Drives the freshness lifecycle.
- Excerpt (optional) — a specific passage you want writers to cite
- Click Save. The new row appears immediately in the table.
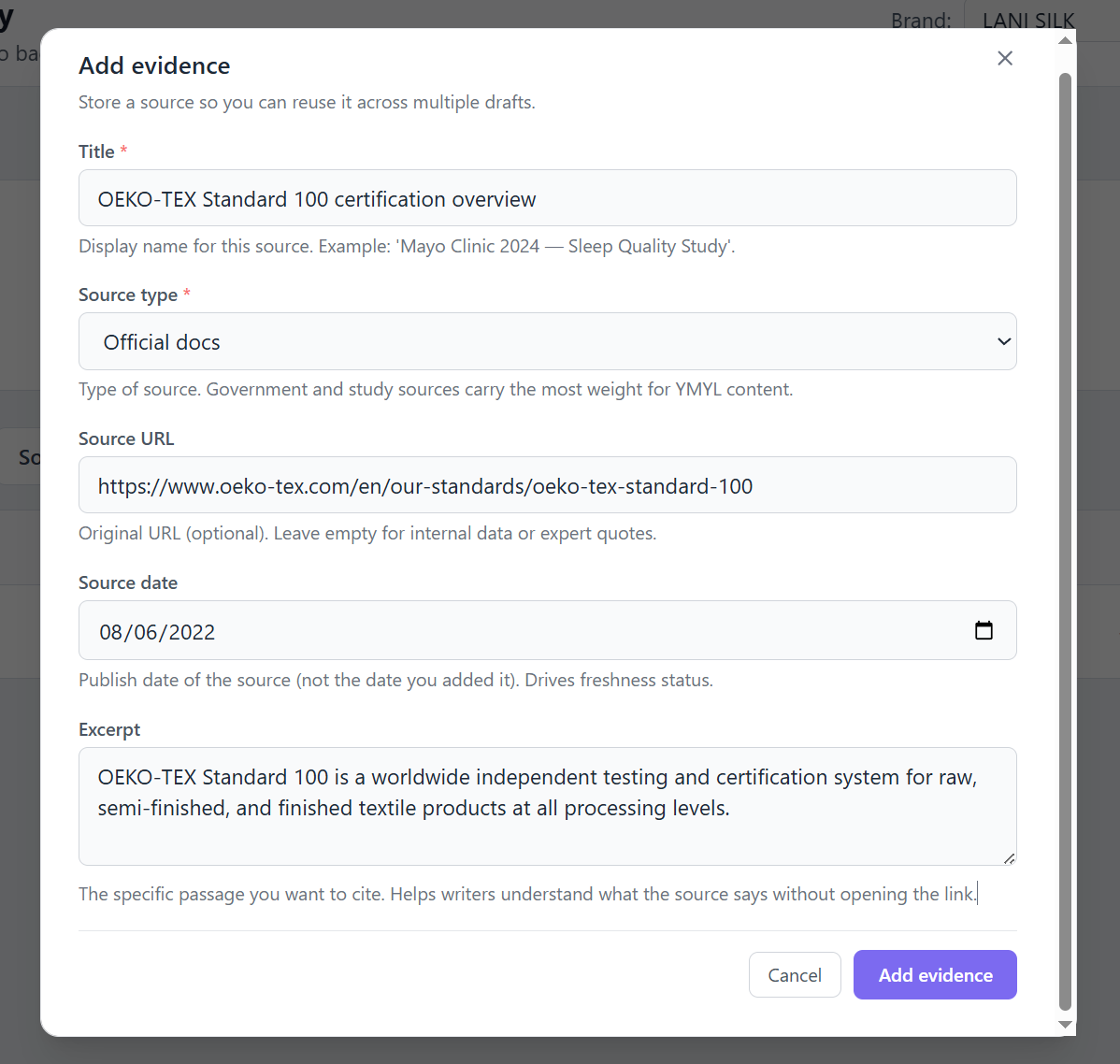 12345
12345- 1Title — display name for the source
- 2Source type — tier signal that drives default strength
- 3Source URL — where reviewers verify the claim (optional)
- 4Source date — publish date, drives freshness lifecycle
- 5Excerpt — specific passage you want writers to cite
Source type — pick the right tier#
Source type drives the trust weight the engines assign. Pick the most specific match:
| Source type | When to use |
| --- | --- |
| government | Government filings: FTC, EU regulations, CPSC, USDA, FDA. Highest trust. |
| official_docs | Certification standards (OEKO-TEX, GOTS, ISO), trade association documents. |
| study | Peer-reviewed research: dermatology, sleep medicine, textile science journals. |
| credible_external | Industry reports (Grand View, Statista) and reputable journalism (NYT, BBC, Reuters). |
| expert | Named expert content: a dermatologist's blog, a textile scientist's article, certified-specialist guides. |
| first_party | Your brand's own data: customer surveys, internal lab tests, proprietary research. |
| internal_data | Internal company documents, sales data, retention metrics. |
If you cannot place a source in one of these seven, do not add it — the engine treats unknown source types as low trust and the evidence will not move the coverage score.
5. Field reference#
The Add Evidence modal has five fields. Two more fields are visible in the table but engine-managed — you do not enter them.
| Field | Required | Purpose | Example |
| --- | --- | --- | --- |
| Title | Yes | Display name for the source. Show what the source is, not where it lives. | OEKO-TEX Standard 100 certification overview |
| Source type | Yes | Tier signal that drives the default strength score. Pick the most specific of the 7 enum values above. | official_docs |
| Source URL | No | Where reviewers verify the claim. Leave empty for internal data or expert quotes. | https://www.oeko-tex.com/en/our-standards/oeko-tex-standard-100 |
| Source date | Yes | Publish date of the source (not the date you added it). Drives the freshness lifecycle. | 2022-08-06 |
| Excerpt | No | A specific passage you want to cite. Helps writers understand the source without opening the link. Keep it concise. | "OEKO-TEX Standard 100 is a worldwide independent testing and certification system…" |
Engine-managed fields (read-only in the table):
| Field | Purpose |
| --- | --- |
| freshness_status | fresh → aging → stale → needs_review. Window varies by source_type. |
| strength_score | 0.0–1.0. Computed from source_type + recency. |
The engine owns the lifecycle fields and never modifies the five fields you enter.
6. Examples for your category#
A useful library is built in two tiers. Curate foundation evidence first (broadly applicable, covers many articles); add product-specific evidence later as your content roadmap demands depth.
Starter sources — foundation evidence#
These eight themes cover most claims you will make. Each gets you 4–5 sources you can reuse across the catalog.
- Health and wellness research — peer-reviewed studies on the category's most-claimed benefits. Treat as YMYL-adjacent: use
studysource type, prefer journal-named sources. - Material science and grading standards — authoritative definitions of any technical claim (e.g. "22 momme", "grade 6A", "100% mulberry"). Source from industry associations or peer-reviewed materials science.
- Certifications and compliance — labels and standards relevant to your products (OEKO-TEX, GOTS, FTC 16 CFR 303, EU 1007/2011, CPSC 16 CFR 1615/1616). Use
governmentorofficial_docs. - Industry reports and market data — Grand View Research, Mordor Intelligence, Statista, IBISWorld for market size, growth trends, consumer preference data.
- Production and sustainability — sericulture process, water/energy impact, sustainable practices. Useful for brand storytelling backed by data.
- Care and maintenance — expert guidance on washing, longevity, fiber degradation. Cite textile care institutes for
experttier. - Competitor benchmarks — direct product specs and pricing from competitor pages plus third-party reviews (Wirecutter, Good Housekeeping). Mix of
first_party(competitor pages) andcredible_external(review outlets). - Safety and allergens — high-bar YMYL territory. Use medical journals and government safety standards. Never paraphrase loosely here.
Product-specific evidence — drilldown#
When a single product page needs depth, pull 3–5 targeted sources for that product (or product category). These supplement the foundation; they do not replace it. Start product-specific work only after you have ~15–20 foundation rows in place.
Recommended order#
- Build foundation (Tier 1) until the library has roughly 15–20 strong rows.
- Move to product-specific (Tier 2) only when a draft fails coverage on a specific product.
- Re-run the GEO Validator after each batch of new evidence to confirm coverage moved.
7. Common mistakes & FAQ#
Anti-patterns#
- Setting Source date to today instead of the source's actual publish date — breaks the freshness lifecycle. A 2018 study marked with today's date is treated as fresh until the next freshness window elapses, so it will never trigger a refresh when it should.
- Using
credible_externalfor peer-reviewed work — downgrades the source. Usestudyfor journals; usecredible_externalonly for editorial outlets. - Pasting a long article as Excerpt — keep excerpts to the part that supports the specific claim. The rest belongs in the source itself, behind the link.
- Adding the same URL twice — duplicate URLs are detected and rejected. Update the existing row instead of creating a parallel one.
- Treating
first_partyas a free pass on YMYL claims — internal data is fine for marketing claims but does not satisfy the validator's evidence requirements for health, finance, legal, or safety topics. Pair it with externalstudyorgovernmentevidence.
FAQ#
What is the difference between brand_asset_upload and manual_added?
brand_asset_upload evidence is imported in bulk from a brand asset (a CSV, a research dossier). manual_added evidence is entered one row at a time in the Add Evidence modal. Both behave identically in the engine; the distinction is provenance, surfaced as a badge in the table.
How do I know what counts as "fresh"?
The freshness window depends on source_type. Government regulations stay fresh for years; market reports go stale within ~12 months. You do not need to set this — the engine does. When a source moves into aging or stale, the Refresh Engine flags it.
Can I delete evidence after it has been cited in a draft? Yes, but the cited drafts will surface a "missing source" warning on next validation. Best practice: replace before you delete. Add the new source first, point the drafts at the new row, then archive the old one.
Why is my coverage still below threshold after adding 20 rows? Coverage is per-claim, not per-row. Twenty rows on one topic cover one set of claims; the rest of your draft can still be uncovered. Open the validator report and look at the per-claim breakdown to see which claims still need evidence.
Is there a maximum library size?
No hard cap. Past a few hundred rows the table view becomes the bottleneck — use filters (by source_type, by freshness_status) to navigate.
Need help curating evidence? See also: Source types explained · Freshness lifecycle · Coverage reports.